Architecture
priint:cloud core services provide a REST API to render input documents (mainly XML) into high quality PDFs. The main component therefore is the priint:cloud rendering service.
The following graph shows abstractly how the priint:cloud rendering service is embedded into a usage scenario.
Big Picture - Integration
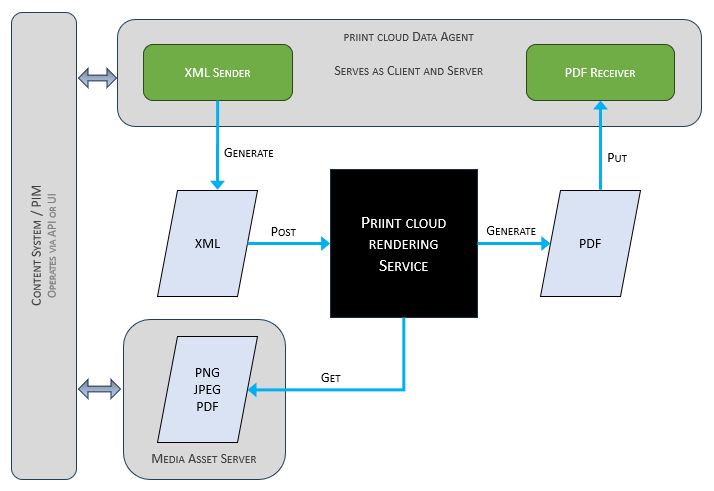
The rendering service is fed with XML data send from data agents, which themselves collect the data from content systems. Content systems in this regard may be everything from full-grown product information systems (PIM) down to simple Excel files.
The rendering service - as a black box here - converts the input into a PDF by using some configurations and templates and sends the resulting file to a PDF receiver. The receiver might be a data agent with an HTTP API, a PIM system, or an FTP server or similar. It is just some kind of file sink.
PDFs will contain pictures which are read during rendering from a CDN, a MAM, or any kind of file provider with HTTP interface.
Data-agents can be specific to content systems and even be implemented as plug-in of content systems. Typically, they act as middleware between content-systems and the rendering service.
Internal Architecture
If we open the black box a little bit it will comprise different internal services under the hood as depicted below:
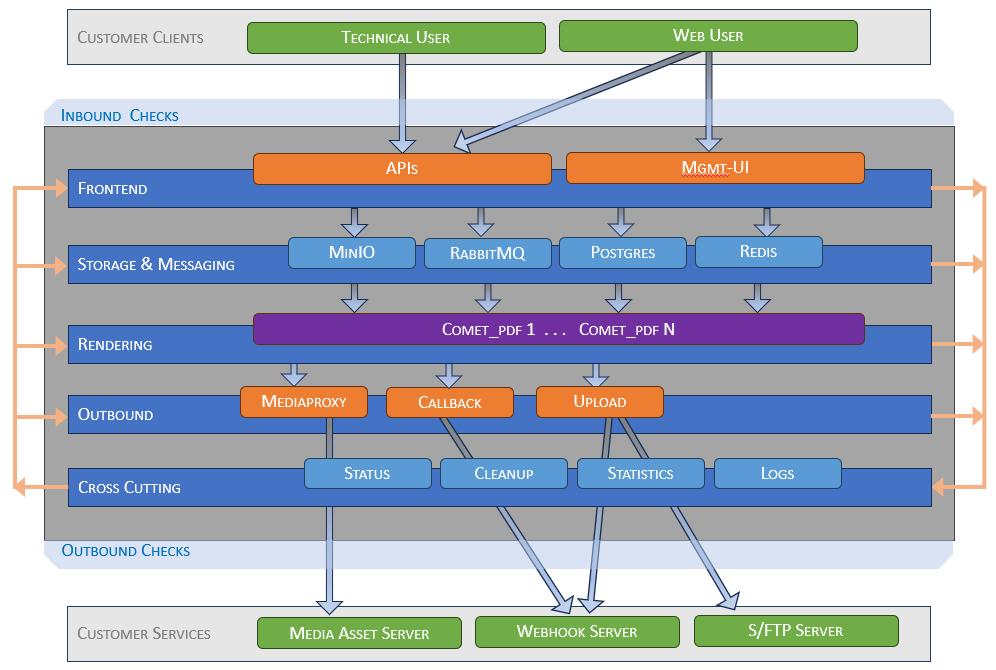
Data agent will act as customer clients (XML senders) and trigger requests to the service. On the other hand they will act as customer services (PDF consumers) and receive requests from the rendering service.
- The frontend layer of the service will analyze requests from technical users (data agents) or web users (in case of the management ui application).
- Requests will be transformed into messages for the internal broker (here RabbitMQ).
- Associated data are stored in an object storage (here MinIO).
- Control data will be read from end written to a relational database (here Postgres) or a distributed cache (here Redis).
- A scalable set of rendering worker (here RenderPdf) will start instances of the priint:comet_pdf renderer to do the actual work.
- The processing of these workers is customizable by the comet xml project containing derivatives of InDesign templates and optional comet scripting code (here Python).
- Artifacts are send to the object storage.
- Outbound traffic in initiated either
- by comet_pdf requesting images which are satisfied through an internal media proxy service handling caching and authentication, or
- by messages to several webhook workers for uploading PDFs to their destinations or notifying (callback) customer services on success or failure.
- Some internal services exist for cross-cutting concerns such as keeping job status, aggregating statistics, writing logs, and janitor tasks (cleanup).
All these services run in Docker containers and are orchestrated by Kubernetes in a cluster which - currently - is hosted in the Google Cloud.